

La documentación oficial y el paper publicado en abril de 2026 usan la denominación Seedance 2.0; en este informe la tomo como la referencia técnica canónica para responder al pedido sobre “SeeDance 2.0”. A abril de 2026, el modelo aparece descrito por ByteDance como un sistema nativo de generación conjunta audio‑video, con arquitectura multimodal unificada, soporte para entradas de texto, imagen, audio y video, y salida de clips de 4 a 15 segundos. En la práctica, el modo I2V utilizable hoy en documentación pública se articula sobre tres patrones: imagen como primer frame, imagen como primer y último frame, y referencias multimodales que combinan imágenes, videos y audios con instrucciones textuales.
La conclusión más importante para un manual serio es esta: Seedance 2.0 debe tratarse, hoy, como un modelo hospedado por API y consola, no como un stack de pesos descargables para inferencia local. Los términos oficiales indican que no se entregan algoritmos, parámetros, pesos ni código del servicio; por eso, la instalación efectiva no consiste en “levantar el modelo” en tu GPU, sino en preparar un cliente robusto —Python, entorno virtual, contenedor, almacenamiento de assets y automatización de polling/descarga — alrededor de la API de BytePlus ModelArk
Para I2V, el estándar operativo actual es: preparar assets en formatos compatibles, hacerlos accesibles por URL pública, crear una tarea asíncrona contra /contents/generations/tasks, consultar su estado, y mover el resultado a almacenamiento persistente antes de que caduquen las URLs temporales. Las referencias oficiales muestran soporte de hasta 9 imágenes, 3 videos y 3 audios, pero advierten que “texto + audio” sin imagen/video y “audio-only” no están soportados; además, los ejemplos oficiales hacen polling cada 30 segundos, lo que deja claro que la latencia es de tipo job asíncrono, no de render interactivo en tiempo real.
También hay dos matices que conviene dejar fijados desde el inicio. Primero, existe una pequeña tensión documental entre el paper —que describe salidas nativas de 480p y 720p— y la documentación comercial actual de ModelArk —que ya expone una opción 1080p para el modelo estándar, pero no para la variante Fast—; para un manual riguroso, lo prudente es tratar 480p/720p como resoluciones nativas públicamente descritas y 1080p como tier de salida de plataforma actualmente disponible en ModelArk para el modelo estándar. Segundo, las políticas y restricciones de derechos de autor, retratos y rostros reales no son accesorias: son parte del modelo de operación. La plataforma restringe el uso directo de referencias con caras reales, ofrece una biblioteca de personajes digitales y un flujo específico para assets de personas reales autorizadas, y mantiene filtros de contenido activados por defecto.
Alcance del manual
El objetivo de este manual es servir como guía única, técnica y práctica, para cuatro perfiles. Para desarrolladores, debe dejar claro cómo autenticar, versionar, contenerizar e integrar el servicio en pipelines. Para investigadores, debe separar lo que está públicamente documentado de lo que no lo está, y distinguir interfaz, capacidades observables y limitaciones declaradas. Para creativos, debe traducir la API a un lenguaje de control cinematográfico: sujeto, acción, cámara, ritmo, iluminación, continuidad y sonido. Para operadores, debe convertir el uso del modelo en un procedimiento repetible: ingestión de assets, envío, monitoreo, archivado y control de riesgos.
La bibliografía primaria para este informe es la combinación de: página oficial del modelo, nota oficial de lanzamiento, tutoriales y referencia de API de ModelArk, lista de modelos y pricing/rate limits, términos del servicio de generación de video, y el paper técnico de abril de 2026. Donde existen materiales en castellano, su valor actual es mayormente introductorio o divulgativo; la especificación operativa útil sigue concentrada en documentación oficial en inglés y chino, por lo que este manual traduce, depura y consolida esa información.
Un principio metodológico de este manual es no rellenar huecos con conjeturas. Seedance 2.0 sí publica una descripción de alto nivel de su arquitectura como unified multimodal audio-video joint generation architecture, pero no publica de manera abierta una especificación completa capa por capa, pesos, recipe exacta de entrenamiento ni procedimiento de despliegue on‑prem. Por eso, en las secciones técnicas de abajo se diferencia cuidadosamente entre arquitectura declarada, interfaz pública observable y inferencias operativas razonables.
Puesta en marcha e instalación
La ruta de entrada oficial es la de ModelArk: cuenta en consola, creación de API key, activación del modelo y consumo por SDK o REST. La documentación oficial de onboarding para Seedance 2.0 indica, además, que el quickstart prepara un entorno Python, instala el SDK y verifica la variable ARK_API_KEY. El SDK Python recomendado se instala con pip install byteplus-python-sdk-v2; la guía oficial de instalación también recomienda actualizar a la última versión para acceder a las capacidades más recientes.
ModelArk soporta, además, aislamiento por región: hoy la documentación pública expone al menos AP Southeast y EU West (Dublín), cada una con su propio base_url, sus endpoints y sus recursos aislados. Esto importa mucho para operación real: la API key, el estado de activación del modelo y los endpoints de inferencia deben corresponder a la misma región. Para equipos europeos, la base de la región EU evita ambigüedad y simplifica trazabilidad regulatoria y de residencia operativa.
La tabla siguiente resume la matriz comparativa de requisitos y hardware. No describe requisitos de inferencia local de Seedance 2.0 —porque el modelo no se distribuye como pesos locales—, sino los entornos prácticos para operar el cliente, preparar assets y acelerar transcodificación/preprocesado. Las recomendaciones de GPU se apoyan en documentación oficial de contenedores, WSL, ROCm y aceleración de FFmpeg, no en una exigencia del modelo hospedado.
| Perfil operativo | SO recomendado | GPU | Cuándo usarlo | Observación crítica |
|---|---|---|---|---|
| Cliente API puro | Linux/Ubuntu o Windows | No obligatoria | Prompting, envío de tareas, polling, archivado | Seedance corre remoto; localmente solo gestionás cliente, assets y resultados |
| Preprocesado con video pesado | Ubuntu | Opcional | Recorte, transcodificación, normalización de ratios, extracción de frames | Conviene usar FFmpeg con aceleración por hardware |
| Pipeline con NVIDIA | Ubuntu + contenedores | Sí, si querés NVENC/NVDEC | Batch de transcodes, proxies, drafts y up/downscale | Requiere driver compatible y NVIDIA Container Toolkit |
| Pipeline con AMD | Ubuntu | Sí, si querés ROCm/AMF | Preprocesado multimedia y sidecars de visión | Depende de GPUs oficialmente soportadas por ROCm |
| Desarrollo en Windows | Windows 11/10 + WSL2 | No obligatoria | Entorno mixto, herramientas Linux y contenedores | Recomendable usar WSL2 para evitar drift entre scripts Windows/Linux |
| Operación en contenedor | Linux o Windows con contenedor Linux | No obligatoria para la API | Reproducibilidad, CI/CD, despliegues consistentes | El contenedor encapsula Python/ffmpeg, no el modelo base |
Instalación en Ubuntu
Para un flujo estable en Ubuntu, la secuencia razonable es: instalar Python 3.12, crear entorno virtual, instalar el SDK de ModelArk y, si vas a tocar video localmente, instalar FFmpeg. La documentación oficial de Seedance 2.0 quickstart usa Python 3.12 en sus scripts automáticos, y la guía general de instalación del SDK confirma byteplus-python-sdk-v2 como paquete recomendado.
python3.12 -m venv .venv
source .venv/bin/activate
python -m pip install -U pip
pip install -U byteplus-python-sdk-v2
sudo apt-get update
sudo apt-get install -y ffmpeg
export ARK_API_KEY="tu_api_key"
export ARK_BASE_URL="https://ark.eu-west.bytepluses.com/api/v3"
Con esto alcanzás el mínimo funcional. Si tus assets van a vivir fuera de la máquina local, la propia documentación oficial recomienda que las referencias se sirvan por URL pública y sugiere usar almacenamiento TOS de BytePlus con lectura pública configurada para los ejemplos de arranque.
Instalación en Windows
En Windows, el camino más limpio para equipos técnicos es usar WSL2. Microsoft documenta la instalación con wsl --install, y Docker documenta que Docker Desktop sobre backend WSL2 permite flujos Linux homogéneos sin mantener dos familias de scripts. Si preferís entorno nativo, podés crear el virtualenv con Python 3.12 y persistir ARK_API_KEY con setx.
wsl --install
# reiniciar
py -3.12 -m venv .venv
.\.venv\Scripts\Activate.ps1
python -m pip install -U pip
pip install -U byteplus-python-sdk-v2
setx ARK_API_KEY "tu_api_key"
setx ARK_BASE_URL "https://ark.eu-west.bytepluses.com/api/v3"Si trabajás con contenedores en Windows, activá el backend WSL2 y mantené el proyecto dentro del filesystem Linux de WSL para evitar penalizaciones de I/O y diferencias de permisos. Esa combinación suele ser la más robusta para pipelines de assets, CI local y jobs auxiliares de FFmpeg.
Instalación en contenedor
Como Seedance 2.0 es remoto, el contenedor ideal es deliberadamente pequeño: Python 3.12, SDK, FFmpeg y tu script. Esto da reproducibilidad real sin fingir un despliegue local del modelo. La propia documentación oficial del quickstart gira alrededor de Python + SDK + polling de tareas; no hay una ruta pública de “self-host”.
FROM python:3.12-slim
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg curl ca-certificates && \
rm -rf /var/lib/apt/lists/*
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY seedance_i2v.py .
CMD ["python", "seedance_i2v.py"]
# requirements.txt
byteplus-python-sdk-v2Para usar GPU dentro del contenedor solo en tareas de preprocesado, no en la inferencia del modelo, la ruta oficial en Linux es distinta según fabricante: NVIDIA Container Toolkit para GPUs NVIDIA y ROCm/AMF para AMD en los casos oficialmente soportados. FFmpeg documenta aceleración de transcodificación tanto sobre NVENC/NVDEC como sobre AMF.
Modelo y modo I2V
A nivel técnico, lo que Seedance 2.0 declara públicamente es una arquitectura unificada, eficiente y a gran escala para generación conjunta audio‑video multimodal. La página oficial del modelo insiste en tres propiedades: estabilidad de movimiento, control “director-level” y referencia multimodal; el paper añade que admite texto, imagen, audio y video como modalidades de entrada y que el modelo Fast existe para escenarios sensibles a latencia. Ese es el suelo firme. Lo que no está públicamente abierto es una especificación detallada de capas, pesos o recipe de entrenamiento que permita reconstruir el sistema localmente.
En términos prácticos, el “modo I2V” no es un botón único sino una familia de interfaces. La documentación de ModelArk y los tutoriales de Seedance 2.0 exponen tres modos especialmente útiles para imagen‑a‑video: primer frame (role="first_frame"), primer y último frame (role="first_frame" y role="last_frame"), y generación por referencias multimodales, donde una o varias imágenes funcionan como referencias de identidad, composición o estilo, pero no necesariamente como fotogramas obligatorios. La guía oficial incluso advierte que, si necesitás consistencia estricta en primero/último frame, conviene usar el modo dedicado y no solo sugerirlo por prompt.
La siguiente visualización resume la arquitectura observable desde la interfaz pública. No pretende revelar internals no publicados; modela el flujo que sí está documentado en API, tutoriales y términos.

La tabla siguiente condensa los formatos de entrada y salida y los límites operativos hoy visibles en documentación pública. La parte de capacidades de salida proviene de la lista oficial de modelos y tutoriales de Seedance 2.0; los formatos de ingestión y límites de tamaño/duración provienen de documentación oficial de assets y APIs relacionadas de la plataforma.
| Elemento | Soporte documentado | Notas operativas |
|---|---|---|
| Texto | Sí | Es la capa semántica principal; sin prompt claro, el resultado cae |
| Imagen de referencia | 0–9 | Roles típicos: first_frame, last_frame, reference_image |
| Video de referencia | 0–3 | Hereda sujeto, movimiento, cámara y estilo general |
| Audio de referencia | 0–3 | Hereda timbre, melodía o diálogo; audio-only no está soportado |
| Combinación “texto + audio” sin imagen/video | No | Restricción explícita en tutorial oficial |
| Imagen: formatos | jpeg, png, webp, bmp, tiff, gif | La plataforma documenta más formatos en algunos contextos; no conviene alejarse de png/jpg para producción |
| Video: formatos | mp4, mov | Para ingestión operativa conviene mp4/H.264 |
| Audio: formatos | mp3, wav | Mantener clips cortos y limpios |
| Duración de salida | 4–15 s | 24 fps según lista oficial |
| Resolución de salida estándar | 480p, 720p, 1080p | El paper habla de 480p/720p nativos; la plataforma hoy expone 1080p para estándar |
| Resolución de salida Fast | 480p, 720p | 1080p no soportado para Fast |
| Aspect ratios | 21:9, 16:9, 4:3, 1:1, 3:4, 9:16 | Conviene recortar antes de subir si la composición es crítica |
| Formato de salida | mp4 | Las URLs de resultados son temporales |
La tabla siguiente resume los parámetros clave y sus efectos. Cuando el nombre exacto del parámetro está visible en ejemplos públicos, lo conservo tal cual; cuando la capacidad está documentada pero el nombre no aparece claramente en snippet público, la describo como ajuste/capacidad de salida.
| Parámetro o ajuste | Ejemplo | Efecto real |
|---|---|---|
model |
dreamina-seedance-2-0-260128 |
Elige estándar o Fast y fija la versión concreta del servicio |
content[].type |
text, image_url, video_url, audio_url |
Define las modalidades que entran en la tarea |
content[].role |
first_frame, last_frame, reference_image, reference_video, reference_audio |
Cambia radicalmente cómo se usa cada asset en la generación |
generate_audio |
true / false |
Activa o desactiva el audio generado/sincronizado |
ratio |
16:9, 9:16, etc. |
Fija encuadre y condiciona composición y costo |
duration |
5, 8, 11 |
Afecta costo, latencia y complejidad de coherencia temporal |
watermark |
true / false |
Controla si la salida se emite con marca; no debe confundirse con “quitar” marcas a posteriori |
return_last_frame |
true |
Devuelve last_frame_url; útil para encadenar iteraciones |
| Resolución de salida | 480p/720p/1080p | Subir resolución aumenta costo y complejidad; 1080p solo estándar |
| Variante Fast | dreamina-seedance-2-0-fast-260128 |
Menor costo y menor latencia, con resignación de calidad máxima |
En relación con latencia y desempeño, el dato más honesto es que la plataforma documenta un flujo asíncrono y no publica un SLA de “X segundos por clip” para Seedance 2.0. El quickstart oficial hace polling cada 30 segundos; el paper y la página oficial solo dicen que existe una variante Fast para escenarios de baja latencia. Traducido a operación real: tratá Seedance como un job queue system y no como una llamada síncrona de baja latencia.
También conviene dejar registradas las limitaciones declaradas por sus propias fuentes: el equipo oficial reconoce que aún hay puntos a mejorar en estabilidad de detalle, hiperrealismo, vitalidad dinámica, precisión de texto renderizado y algunos efectos de edición complejos; para audio, también menciona distorsiones ocasionales. Si un manual no incorpora estas limitaciones, empuja al usuario a sobredimensionar el modelo y eso termina en debugging innecesario.
Guía de uso y flujos de trabajo reproducibles
El flujo operativo recomendado para I2V es sencillo en estructura y exigente en disciplina: definir modo, limpiar assets, subir por URL accesible, crear tarea, hacer polling, persistir resultado, iterar con edición o extensión. El error más común en equipos creativos es intentar resolver con prompt lo que debería resolverse con assets; el error más común en equipos técnicos es subir assets “sucios” y esperar que la API corrija relaciones de aspecto, encuadres o continuidad por sí sola. Los ejemplos oficiales muestran que Seedance responde mucho mejor cuando el rol de cada input está bien delimitado.
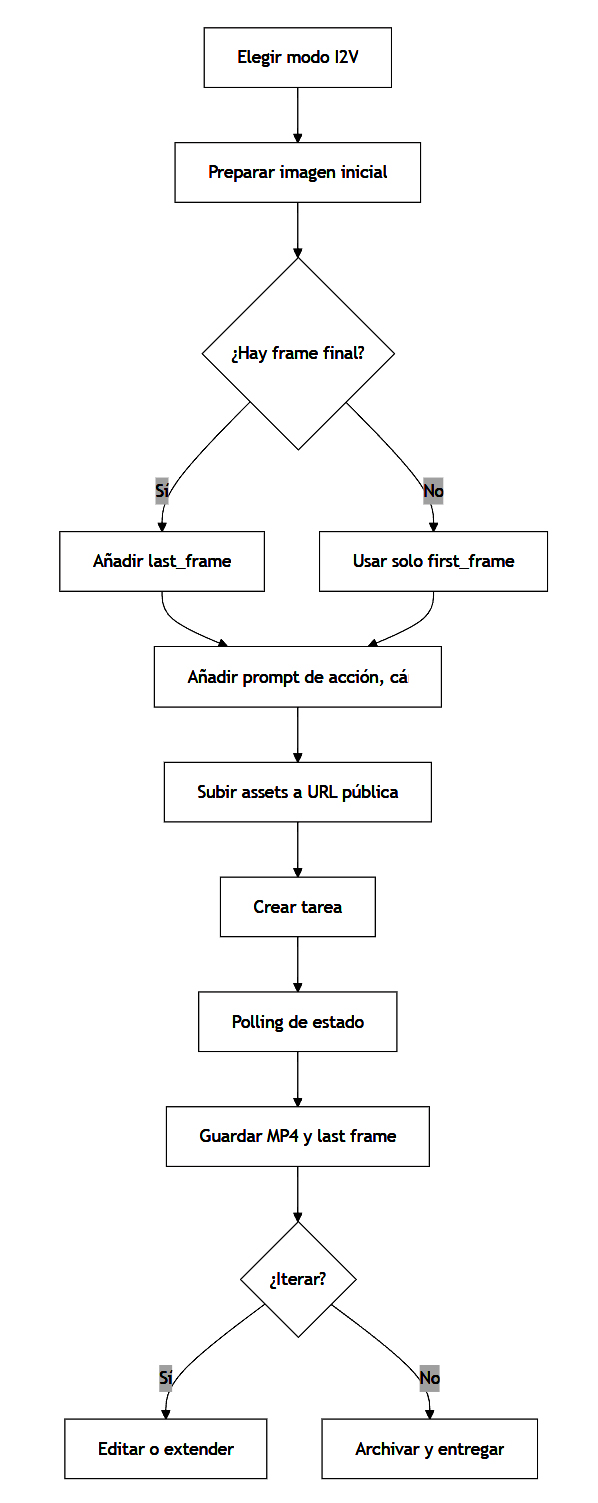
Comandos mínimos
La referencia pública de tutoriales indica que la creación de tareas se hace por POST /contents/generations/tasks; el SDK oficial de Python encapsula esto en client.content_generation.tasks.create(...). El siguiente curl es la forma más directa de testear la cadena sin escribir demasiado código.
curl -X POST "$ARK_BASE_URL/contents/generations/tasks" \
-H "Authorization: Bearer $ARK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "dreamina-seedance-2-0-260128",
"content": [
{
"type": "text",
"text": "Plano medio cinematográfico. La mujer del retrato gira lentamente hacia cámara, el cabello se mueve con una brisa suave, luz cálida de atardecer, dolly in sutil, alta coherencia facial."
},
{
"type": "image_url",
"image_url": { "url": "https://TU_BUCKET_PUBLICO/frame_inicial.png" },
"role": "first_frame"
}
],
"generate_audio": false,
"ratio": "16:9",
"duration": 5,
"watermark": true
}'Para trabajo real, el SDK oficial es más cómodo porque reduce errores de autenticación, serialización y polling. El patrón de abajo replica la estructura de los ejemplos oficiales y añade un extractor genérico de URLs para no depender de un shape de respuesta rígido.
# seedance_i2v.py
import json
import os
import time
from typing import Any, Iterable
from byteplussdkarkruntime import Ark
def to_dict(obj: Any) -> Any:
if hasattr(obj, "model_dump"):
return obj.model_dump()
if hasattr(obj, "to_dict"):
return obj.to_dict()
if isinstance(obj, dict):
return obj
if isinstance(obj, (list, tuple)):
return [to_dict(x) for x in obj]
if hasattr(obj, "__dict__"):
return {k: to_dict(v) for k, v in obj.__dict__.items()}
return obj
def find_urls(node: Any) -> Iterable[str]:
if isinstance(node, dict):
for v in node.values():
yield from find_urls(v)
elif isinstance(node, list):
for v in node:
yield from find_urls(v)
elif isinstance(node, str) and node.startswith("http"):
yield node
BASE_URL = os.getenv("ARK_BASE_URL", "https://ark.eu-west.bytepluses.com/api/v3")
API_KEY = os.getenv("ARK_API_KEY")
MODEL = os.getenv("SEEDANCE_MODEL", "dreamina-seedance-2-0-260128")
FIRST_FRAME_URL = os.getenv("FIRST_FRAME_URL", "https://TU_BUCKET_PUBLICO/frame_inicial.png")
LAST_FRAME_URL = os.getenv("LAST_FRAME_URL") # opcional
PROMPT = os.getenv(
"PROMPT",
"Primer plano cinematográfico. El personaje respira, sonríe apenas y gira la cabeza hacia la izquierda. Cámara fija con micro movimiento natural, profundidad de campo suave, iluminación dorada."
)
if not API_KEY:
raise RuntimeError("Falta ARK_API_KEY")
client = Ark(base_url=BASE_URL, api_key=API_KEY)
content = [
{"type": "text", "text": PROMPT},
{"type": "image_url", "image_url": {"url": FIRST_FRAME_URL}, "role": "first_frame"},
]
if LAST_FRAME_URL:
content.append(
{"type": "image_url", "image_url": {"url": LAST_FRAME_URL}, "role": "last_frame"}
)
create_result = client.content_generation.tasks.create(
model=MODEL,
content=content,
generate_audio=False,
ratio="16:9",
duration=5,
watermark=True,
return_last_frame=True,
)
task_id = create_result.id
print(f"Tarea creada: {task_id}")
while True:
result = client.content_generation.tasks.get(task_id=task_id)
payload = to_dict(result)
status = payload.get("status") or getattr(result, "status", None)
print(f"Estado: {status}")
if status == "succeeded":
print(json.dumps(payload, indent=2, ensure_ascii=False))
urls = sorted(set(find_urls(payload)))
print("URLs detectadas:")
for u in urls:
print(" -", u)
break
if status == "failed":
print(json.dumps(payload, indent=2, ensure_ascii=False))
raise RuntimeError("La generación falló")
time.sleep(30)
Si querés notebook, no hace falta duplicar el flujo: repartí el script anterior en cuatro celdas —instalación, cliente, creación de content, polling—. Esa es, de hecho, la versión más sana de “notebook reproducible” para este caso. La guía oficial deja claro que el quickstart ya funciona como un pipeline muy simple de “crear tarea → consultar estado → obtener URL final”.
# Celda 1
%pip install -U byteplus-python-sdk-v2# Celda 2
import os, time, json
from byteplussdkarkruntime import Ark
client = Ark(
base_url=os.getenv("ARK_BASE_URL", "https://ark.eu-west.bytepluses.com/api/v3"),
api_key=os.getenv("ARK_API_KEY"),
)# Celda 3
create_result = client.content_generation.tasks.create(
model="dreamina-seedance-2-0-260128",
content=[
{"type": "text", "text": "Plano medio, movimiento suave, mirada a cámara, luz de estudio difusa."},
{"type": "image_url", "image_url": {"url": os.getenv("FIRST_FRAME_URL")}, "role": "first_frame"},
],
generate_audio=False,
ratio="16:9",
duration=5,
watermark=True,
)
task_id = create_result.id
task_id# Celda 4
while True:
result = client.content_generation.tasks.get(task_id=task_id)
payload = result.model_dump() if hasattr(result, "model_dump") else result.__dict__
print(payload.get("status"))
if payload.get("status") in {"succeeded", "failed"}:
print(json.dumps(payload, indent=2, ensure_ascii=False))
break
time.sleep(30)Prompts que funcionan mejor
Aunque la guía 2.0 pública indexable no expone todos sus bullets en texto plano, los ejemplos oficiales de Seedance 2.0 y las guías previas oficiales de la familia Seedance convergen en una disciplina de prompting bastante clara: describir sujeto, acción, orden temporal, escena, cámara y cualidad visual o sonora, evitando contradicciones con la imagen de entrada y privilegiando formulaciones positivas y observables. En otras palabras: menos “estilo abstracto” y más “instrucción cinematográfica comprobable”.
La tabla siguiente ofrece los ejemplos comparativos de prompts con resultados esperados que más rinden en práctica para I2V. No son prompts oficiales copiados; son plantillas operativas derivadas de las capacidades y ejemplos documentados.
| Caso de uso | Inputs | Prompt recomendado | Resultado esperado |
|---|---|---|---|
| I2V simple desde retrato | 1 imagen first_frame |
“Primer plano cinematográfico. El personaje parpadea, respira y gira lentamente hacia cámara. Microgestos naturales, profundidad de campo suave, luz cálida de atardecer.” | Movimiento facial y corporal mínimo, continuidad alta de identidad |
| I2V con destino fijo | 1 imagen first_frame + 1 imagen last_frame |
“Transición limpia y físicamente plausible entre el primer y el último frame. La cámara avanza con un dolly in suave y el personaje cambia de expresión con naturalidad.” | Interpolación estable con llegada creíble al frame final |
| Producto en packshot animado | 1 imagen first_frame |
“Plano de producto sobre superficie negra. La cámara orbita 20 grados, reflejo controlado, luz especular premium, humo muy sutil de fondo.” | Clip comercial corto, útil para e‑commerce o teaser |
| Shot estilizado con referencia visual | 1 imagen first_frame + 1 reference_image |
“Mantén la identidad del sujeto del primer frame y adopta la paleta, contraste y textura cinematográfica de la imagen de referencia. Cámara handheld muy suave.” | Conserva sujeto y transfiere look general |
| Edición guiada por texto | 1 reference_video + texto |
“Sustituye el objeto central por una escultura de mármol blanco. Conserva cámara, timing y composición del video de referencia.” | Edición de elemento con preservación del resto |
| Integración narrativa | 2–3 reference_video + texto |
“Une los clips con transiciones de cámara coherentes. El movimiento entra por la ventana del primer clip, avanza al interior y termina dentro de la obra del tercer clip.” | Stitching/continuación con lógica espacial y visual |
Datasets de prueba y datos sintéticos
Para pruebas reproducibles conviene distinguir entre datos sintéticos y datasets públicos. Los sintéticos sirven para validar la cadena técnica sin ruido legal; los públicos sirven para comparar modos y prompts sobre material conocido. Para stills, COCO es suficiente; para clips, DAVIS y UCF101 son dos bases muy útiles y bien conocidas. COCO aporta imágenes variadas con contexto; DAVIS aporta secuencias cortas de alta calidad; UCF101 aporta acciones humanas diversas y clips abundantes.
Una plantilla mínima de datos sintéticos puede generarse localmente con Python: dos frames estilizados y un tono WAV. Después, subilos a tu almacenamiento público y usalos como first_frame/last_frame.
# make_synthetic_assets.py
from PIL import Image, ImageDraw
import math
import wave
import struct
W, H = 1280, 720
for name, bg, accent, eye_dx in [
("frame_a.png", (18, 22, 38), (235, 180, 80), -20),
("frame_b.png", (26, 14, 24), (120, 210, 245), 20),
]:
img = Image.new("RGB", (W, H), bg)
d = ImageDraw.Draw(img)
d.ellipse((420, 120, 860, 560), fill=(220, 205, 190))
d.ellipse((520 + eye_dx, 270, 560 + eye_dx, 300), fill=(20, 20, 20))
d.ellipse((700 + eye_dx, 270, 740 + eye_dx, 300), fill=(20, 20, 20))
d.rectangle((460, 560, 820, 660), fill=accent)
d.text((40, 40), name, fill=(255, 255, 255))
img.save(name)
sample_rate = 44100
duration_s = 2.0
freq = 440.0
with wave.open("tone.wav", "w") as wav:
wav.setnchannels(1)
wav.setsampwidth(2)
wav.setframerate(sample_rate)
for i in range(int(sample_rate * duration_s)):
value = int(32767 * 0.2 * math.sin(2 * math.pi * freq * i / sample_rate))
wav.writeframes(struct.pack("<h", value))
Operación eficiente y optimización
La optimización más importante no es de CUDA ni de cuantización: es elegir bien la variante del modelo y estructurar la iteración. La propia documentación de Seedance 2.0 dice que Fast conserva las mismas capacidades, pero recomienda la versión estándar cuando buscás calidad máxima y la variante Fast cuando priorizás costo y velocidad. La documentación de pricing confirma, además, que Fast tiene tarifa menor y que 1080p no está soportado allí. En un pipeline serio, eso se traduce en una regla muy simple: Fast para exploración y drafts; estándar para tiros finales.
En throughput, hay que respetar los límites de la lista oficial de modelos: para online inference se documentan topes por defecto de 600 RPM / concurrencia 10 para enterprise y 180 RPM / concurrencia 3 para cuentas individuales. Eso obliga a diseñar colas, backoff y persistencia de task_id. En la práctica, el batching útil no es “batch dentro del modelo” —no está expuesto así para Seedance 2.0 en sus ejemplos públicos— sino batching de tareas respetando rate limits, con una cola de workers que separa ingestión, submit y polling.
La optimización de recursos locales sí tiene sentido en el preprocesado. Si trabajás con muchas imágenes y clips, recortá y normalizá antes de subir. Seedance acepta varios aspect ratios, pero subir ya en ratio final reduce sorpresas de composición; acortar referencias de video a lo estrictamente necesario reduce costo y complejidad; convertir a MP4/H.264 y JPG/PNG robustos reduce fallos de ingestión. Para infraestructura con GPU local, FFmpeg documenta aceleración por NVENC/NVDEC y AMF; eso te permite preparar assets, generar proxies y versionar borradores sin castigar CPU.
En este contexto, la cuantización solo aplica a modelos auxiliares que vivan en tu lado del pipeline —captioners, upscalers, detectores, moderadores propios, clasificadores de calidad—, no a Seedance 2.0 en sí. Los términos oficiales dejan claro que el servicio no expone pesos ni código del modelo base; por lo tanto, hablar de cuantizar Seedance 2.0 “para correrlo más barato localmente” no es una optimización realista, sino una categoría equivocada de problema.
Una estrategia de producción robusta suele verse así. Primero, usar Fast a 480p o 720p para explorar prompt, movimiento y cámara. Segundo, congelar prompt y assets. Tercero, emitir estándar en la resolución necesaria. Cuarto, guardar inmediatamente el MP4 y el last_frame_url, porque las URLs son temporales. Quinto, si vas a hacer chaining, reutilizar outputs propios o moverlos a almacenamiento durable; la propia documentación recomienda transferir resultados a TOS con anticipación para reuso y backup.
En integración de pipelines, el patrón recomendado es desacoplar cinco fases: ingestión de assets, submit de tarea, polling, persistencia duradera y postproceso. Si además necesitás continuidad narrativa, conviene guardar no solo el video final sino también el last_frame_url y la versión exacta del model usado, porque los IDs están versionados y pueden cambiar entre releases de plataforma.
Seguridad, privacidad y consideraciones éticas
En seguridad y privacidad, ModelArk publica tres hechos especialmente relevantes. Primero, el tráfico usa HTTPS y la plataforma documenta mecanismos adicionales de cifrado a nivel de aplicación para ciertos escenarios. Segundo, declara procesar datos del cliente bajo instrucciones del cliente y afirma que no usa prompts ni outputs para entrenar los modelos base sin consentimiento separado. Tercero, documenta residencia/processing en Malaysia, Indonesia y/o EU/EEA, con aislamiento entre clientes y controles de acceso internos.
Ahora bien, hay que leer la letra chica completa. El esquema de cifrado de aplicación documentado por la plataforma no se presenta como una solución universal para cualquier flujo ni para cualquier SDK: la página técnica que lo describe habla de soporte actual en Python SDK y, en ese documento concreto, lo limita a modelos de diálogo Skylark. Para Seedance 2.0, la forma prudente de redactar el manual es decir que la protección efectiva hoy documentada para su uso corriente descansa en HTTPS, segmentación regional, control de acceso, manejo correcto de API keys y gobierno de outputs, no en asumir gratis una capa extra de cifrado de aplicación para video si tu workflow no la tiene expresamente certificada.
El filtro de contenido también importa operativamente. BytePlus documenta un Content Pre-filter System integrado en ModelArk, activado por defecto al crear endpoints y configurable por el usuario, pero aclara que incluso si lo desactivás siguen existiendo políticas base de seguridad. Si el filtro interviene, la respuesta puede marcar finish_reason = "content_filter". A la vez, la plataforma retiene por un período limitado logs y datos filtrados relacionados con seguridad; la documentación de data processing dice que inputs y outputs disparados por el filtro pueden retenerse 180 días en Malaysia con fines de content safety.
En ética y cumplimiento, el punto más delicado es el uso de personas reales. La documentación pública del tutorial de Seedance 2.0 dice que no se soporta la carga directa de imágenes o videos de referencia con rostros reales; para esos casos, la plataforma o bien confía ciertas salidas generadas bajo tu cuenta durante 30 días, o bien ofrece un flujo de real-human assets con verificación y autorización. Los términos específicos del servicio de generación de video también dicen que, si tus materiales incluyen retratos de personas reales, debés obtener autorización del propio titular de derechos y usar las herramientas de autenticación provistas por BytePlus o aportar soporte documental.
Los términos oficiales agregan otras obligaciones que un manual serio no puede esconder: no remover marcas de agua o señales de procedencia cuando existan, no usar inputs/outputs para entrenar modelos competidores, no inferir identidad o datos sensibles de personas mediante “vision features”, y no dar por sentado que tus outputs serán únicos. En términos legales y de reputación, esto encaja con la presión pública reciente sobre Seedance 2.0 por posibles infracciones de copyright y de likeness: aun cuando el producto siga ganando capacidad multimodal, el margen de error empresarial más caro hoy no suele ser técnico, sino de derechos y compliance.
La regla práctica es simple: para campañas, publicidad, branded content o rostro humano identificable, usá personajes digitales o assets reales autorizados y verificados. Para exploración creativa general, evitá IP protegida, celebridades, personajes registrados y “lookalikes” sin autorización. Lo que parece un prompt ingenioso puede convertirse muy rápido en un problema contractual, reputacional o incluso de bloqueo del asset.
Problemas frecuentes, FAQ y fuentes principales
El troubleshooting más útil para Seedance 2.0 es menos “místico” de lo que suele parecer: casi todos los fallos prácticos caen en una de estas categorías: autenticación/región, asset inaccesible, combinación modal no soportada, expiración de URL, o expectativas incorrectas sobre el rol del input. La siguiente tabla resume los casos más comunes. Los remedios salen de la propia documentación de quickstart, región, retrieve/list y restricciones modales.
| Síntoma | Causa probable | Solución práctica |
|---|---|---|
401 o autorización fallida |
API key ausente o de otra región | Verificá ARK_API_KEY y ARK_BASE_URL; AP y EU están aisladas |
| La tarea se crea pero falla | URL de asset no accesible públicamente | Subí a bucket público o storage accesible desde Internet |
| El modelo “ignora” el frame final | Se usó como referencia, no como frame obligatorio | Enviá la imagen con role="last_frame" |
| La identidad deriva con el tiempo | Prompt demasiado ambicioso o assets contradictorios | Reducí acciones, usá primer+último frame o referencias visuales más limpias |
| No hay audio aunque aportaste audio | Intento de audio-only o texto + audio sin visual |
Añadí imagen o video; esas combinaciones están restringidas |
| La URL final ya no funciona | Expiró la ventana temporal | Persistí el MP4 inmediatamente en tu storage |
| No encontrás tareas viejas | La lista solo consulta histórico reciente | Guardá task_id y resultados en tu propia base; el listado oficial cubre 7 días |
| Output bloqueado por filtros | Content pre-filter o baseline safety | Revisá prompt/materiales y si el endpoint usa filtro activo |
| Rostro real rechazado | Restricción de referencias con caras reales | Usá digital characters o el flujo de real-human assets autorizados |
FAQ
¿Puedo instalar Seedance 2.0 localmente y cuantizarlo?
No en el sentido habitual de “bajar pesos y correr inferencia propia”. La documentación contractual dice que BytePlus no entrega pesos, algoritmos ni código del servicio; la instalación real es la del cliente y la automatización que lo rodea.
¿Cuál es el mejor modo I2V?
Si necesitás máxima continuidad con una sola imagen, usá first frame. Si necesitás llegar a una pose/encuadre final específico, usá first + last frame. Si querés mezcla de identidad, look y dinámica, usá multimodal reference con roles bien definidos.
¿Fast reemplaza al modelo estándar?
No. Fast comparte capacidades, pero la propia guía oficial lo recomienda cuando priorizás costo y velocidad sobre calidad extrema; además, 1080p no está soportado en Fast.
¿Qué resolución conviene usar?
Para exploración, 480p o 720p. Para entrega, estándar a 720p o 1080p si tu cuenta y caso lo justifican. Tratá 1080p como un tier de salida actual de plataforma, no como una resolución “nativa” inequívocamente documentada por el paper.
¿Cuánto tardan las generaciones?
La documentación pública no publica una latencia cerrada por job. Lo que sí documenta es un flujo asíncrono y ejemplos que consultan estado cada 30 segundos; por eso la operación correcta es cola + polling + persistencia.
¿Puedo usar fotos de personas reales?
No como simple upload directo de referencia en los casos restringidos por la plataforma. Para uso serio de personas reales necesitás el flujo de autorización/verificación, o recurrir a assets verificados/biblioteca de personajes digitales.
¿Los outputs entrenan automáticamente el modelo?
La documentación oficial del servicio de video dice que inputs y outputs no se usan para entrenar los modelos base salvo consentimiento separado. Aun así, sigue habiendo logs/retención limitada ligados a content safety cuando interviene el filtro.
Fuentes principales
Las fuentes que deberían formar la columna vertebral de cualquier versión extensa de este manual son estas:
- Página oficial del modelo Seedance 2.0 y nota oficial de lanzamiento, para capacidades declaradas, posicionamiento del producto y benchmark interno.
- Paper “Seedance 2.0: Advancing Video Generation for World Complexity”, para la definición pública de la arquitectura y el marco técnico general.
- Seedance 2.0 series tutorial, para quickstart, ejemplos oficiales, roles de inputs, polling y restricciones modales.
- Model list y pricing de ModelArk, para IDs de modelo, formatos, frame rate, rate limits y diferencias estándar/Fast.
- API Reference de video generation, especialmente create/retrieve/list task, para endpoint operativo, URLs temporales y ventana de consulta histórica.
- Security & trust / data processing / content pre-filter / specific terms, para privacidad, entrenamiento, cifrado, filtros y licencias de uso.
- Documentación oficial de entorno para contenedores y aceleración local auxiliar: Docker Desktop, WSL2, NVIDIA Container Toolkit, ROCm y FFmpeg.
- Datasets públicos de referencia: COCO, DAVIS y UCF101, útiles para test y benchmarking manual.
En una frase, el manual más efectivo sobre Seedance 2.0 I2V no es el que “sabe más teoría” sino el que entiende mejor su condición real de producto: modelo hospedado, multimodal, asíncrono, fuertemente gobernado por roles de input, con gran potencia creativa, pero también con límites técnicos, temporales y legales muy concretos. Si esa premisa queda clara, casi todas las decisiones correctas de instalación, prompting, integración y compliance caen por su propio peso.